
Leetcode Roasting of the Day: Replace Words
Let’s roast! Today’s Leetcode challenge is: 648. Replace Words
Given a list of dictionary words, replace all words in the given sentence that has the prefix of the word match to the dictionary word, into that prefix. So, if we have a dictionary word “cat” and a sentence “the cattle”, we replace “cattle” into “cat” since “cat” is a prefix of “cattle”, hence producing the resulting sentence “the cat”.
It is almost like regex replacement. But of course, using regex is not an option in C (we can do with C++ although slow, except using Hana Dusiková’s Static Regex). So, my thought initially is already building a simple regex parser. The idea is that we put the dictionary words into a tree-like structure, technically building a lexer, then we parse the string and match that by following the tree.
Roasting the Leetcode Solution
The solution by Leetcode admin is basically the same. But in here we want to roast and of course, their code is roastable. Let’s check their code:
class TrieNode {
public:
bool isEnd;
vector<TrieNode*> children;
TrieNode() : children(26, nullptr) { isEnd = false; }
};
class Trie {
private:
TrieNode* root;
public:
Trie() { root = new TrieNode(); }
void insert(string word) {
TrieNode* current = root;
for (char c : word) {
if (current->children[c - 'a'] == nullptr) {
current->children[c - 'a'] = new TrieNode();
}
current = current->children[c - 'a'];
}
current->isEnd = true;
}
// Find the shortest root of the word in the trie
string shortestRoot(string word) {
TrieNode* current = root;
for (int i = 0; i < word.length(); ++i) {
char c = word[i];
if (current->children[c - 'a'] == nullptr) {
// There is not a corresponding root in the trie
return word;
}
current = current->children[c - 'a'];
if (current->isEnd) {
return word.substr(0, i + 1);
}
}
// There is not a corresponding root in the trie
return word;
}
};
class Solution {
public:
string replaceWords(vector<string>& dictionary, string sentence) {
istringstream sStream(sentence);
Trie dictTrie;
for (string word : dictionary) {
dictTrie.insert(word);
}
// Replace each word in sentence with the corresponding shortest root
string word;
string newSentence;
while (getline(sStream, word, ' ')) {
newSentence += dictTrie.shortestRoot(word) + " ";
}
newSentence.pop_back(); // remove extra space
return newSentence;
}
};
Well, I should give a credit for them making it very OOP and actually quite clean look. But of course, there are stuff that raises my eyebrow here. Let’s go one by one.
1. Using std::vector For Fixed Size Array
class TrieNode {
public:
bool isEnd;
vector<TrieNode*> children;
TrieNode() : children(26, nullptr) { isEnd = false; }
};
This is the first bad programming practice. TrieNode definition needs to store the reference to the children of the node. Since we are working with a lower-case English alphabet, there are only 26 possible characters, meaning at most 26 possible children. And since we are going to simplify selecting the child based on the character, we better to allocate entire 26 rows from the beginning, essentially making it as a simple hashtable with the character as the key. Since we already know the size of the required table, and we are not going to dynamically add or remove any element, using std::vectoris an EXTREMELY BAD CHOICE. You MUST use simple array, or even better std::array
Why? Because std::vector will introduce DOUBLE INDIRECTION. std::vector internally stores a pointer to the underlying storage, the current size, and the maximum reserved storage. To access an element, you will have to load the address of the std::vector internal pointer in the TrieNode, then load the data from the underlying storage. If you are using simple array or std::array, you will only perform a single indirection, because you only need to compute the offset directly from the TrieNode address.
2. Using Naked New
class Trie {
private:
TrieNode* root;
public:
Trie() { root = new TrieNode(); }
void insert(string word) {
TrieNode* current = root;
for (char c : word) {
if (current->children[c - 'a'] == nullptr) {
current->children[c - 'a'] = new TrieNode();
}
current = current->children[c - 'a'];
}
current->isEnd = true;
}
};
Guys, come on. It is 2024 already and you are still using naked new? Although, okay, it is only a competitive programming and you don’t really care about “cleanliness”, but please just make writing good C++ a habit. Naked new is so 2003. Always resort to std::unique_ptr and std::make_unique whenever you can. In this case, they should actually use std::unique_ptr as type for the std::vector (or std::array in the correct one). But then, this pattern using new (or std::make_unique if being corrected) carries an additional baggage, which is:
3. Multiple Allocation
malloc is an expensive function. Calling malloc multiple times, including via new operator, pressures the memory management system in your program, which should be avoided for a performant program. A highly performing program should minimize the call to allocator function by precomputing the required storage. This is also why C++ standard library provides template to implement our own custom allocator, to avoid such case.
Why malloc is expensive? It is because malloc perform accounting using linked-list. The linked-list represents a free-list, where malloc may be able to provide you space. malloc needs to traverse the linked list to find suitable spot with the right size to be given to its caller, and request extension of the available address space to the operating system in case the current heap size cannot fit a new allocation anymore. Not only that, malloc will give you any arbitrary address it can be given to its caller that fits to the requested size. The address may be spreaded over different memory page, reducing the performance of memory access because of cache thrashing. Making one big allocation instead of multiple smaller allocation may improve performance as it increases the locality of the memory.
4. I know you are a Java programmer if you pass std::string by value in parameter
class Trie {
// Find the shortest root of the word in the trie
string shortestRoot(string word) {
TrieNode* current = root;
for (int i = 0; i < word.length(); ++i) { char c = word[i]; if (current->children[c - 'a'] == nullptr) {
// There is not a corresponding root in the trie
return word;
}
current = current->children[c - 'a'];
if (current->isEnd) {
return word.substr(0, i + 1);
}
}
// There is not a corresponding root in the trie
return word;
}
};
Please don’t do this. Passing by value means DEEP COPYING the entire std::string. Always pass string either by std::string_view or std::string const& to pass by reference. I know you come from Java or C# if you pass string like that in C++. String in C++ IS NOT A REFERENCE unless you specify it as reference! Passing string by value has almost zero use except if you are going to std::move the string elsewhere without modifying the string in the caller. But still, it is a bad practice.
5. Parsing using C++ stream
string replaceWords(vector<string>& dictionary, string sentence) {
istringstream sStream(sentence);
Trie dictTrie;
for (string word : dictionary) {
dictTrie.insert(word);
}
// Replace each word in sentence with the corresponding shortest root
string word;
string newSentence;
while (getline(sStream, word, ' ')) {
newSentence += dictTrie.shortestRoot(word) + " ";
}
newSentence.pop_back(); // remove extra space
return newSentence;
}
Of course we are all allowed to be lazy. But lazy also means slow performing program. In this solution function, it tokenize the words using std::istringstream and std::getline function. This is ultra unnecessary. Why not just simply loop? Or perhaps using std::ranges::find to find the next space character then build std::string_view from it. Look how many unnecessary string copying here:
- The first allocation of std::istringstream in this implementation will copy the sentence string to the internal std::istringstream buffer
- For-each looping the dictionary copies each string in the dictionary to the iterator variable word, which will then copied again to the insert function
- std::getline function copies again the internal buffer of std::istringstream into local variable word on each sentence
- discard the returned string from shortestRoot function after string value has been appended to the newSentence string
- Appending new string on each iteration, meaning that if the new string should be larger than the currently allocated space, std::string needs to reallocate larger space, and copy previous string to the new one
Then you complain “Ahh C++ is so slower than Java”
It is your BRAIN that is slow.
What I did
1. Use array in the tree node while don’t need to initialize all elements at once
Similar to the Leetcode solution, I made a tree, but a more efficient tree. I don’t use std::vector, instead I use regular array. I don’t want to incur a cost of initializing the children table to nullptr, so I use a bitmasking to indicate whether the specified index in the map has a value or not. So I can simply initialize 2 fields (hasNext bitmask and terminate boolean) rather than 1 + 26 fields.
struct CharNode
{
CharNode* nextTable[26];
bool terminate { false };
uint32_t hasNext { 0 };
CharNode* get_next(char nc)
{
uint32_t mask = 1 << nc - 'a';
if(hasNext & mask)
return nextTable[nc - 'a'];
else
return nullptr;
}
CharNode* set_next(char nc, CharNode* node)
{
uint32_t mask = 1 << nc - 'a';
hasNext |= mask;
return nextTable[nc - 'a'] = node;
}
};
2. Allocate the tree node ONCE on the stack
We can calculate the maximum possible CharNode by accumulating the string length of the dictionary word. Then, we dynamically allocate local array with the number. This is actually not a standard C++, but it is accepted in many compilers, including GCC and Clang. It is extremely useful so we avoid allocating any heap and maintaining locality of our data.
std::string replaceWords(std::vector<std::string> const& dictionary, std::string const& sentence)
{
CharNode root;
int size = std::accumulate(dictionary.begin(), dictionary.end(), 0, [] (int s, std::string const& ref) { return s + ref.size(); });
CharNode pool[size];
size_t currAlloc = 0;
...
}
3. When we already found the shorter word, just ignore the rest
The problem statement said that we should select the shorter prefix word from the dictionary. So if we have both “dog” and “do”, we will always select the “do” prefix over “dog”. Therefore, we can use this to optimize our tree-building section by ignoring the rest of the word if we already traverse and found a terminating character. So, we don’t need to traverse all characters from all words. This also avoids sorting as I think sorting will give more penalties rather than optimization.
std::string replaceWords(std::vector<std::string> const& dictionary, std::string const& sentence)
{
...
for(auto& str : dictionary)
{
CharNode* current = &root;
for(auto ch : str)
{
if(current->terminate)
break;
else if(auto next = current->get_next(ch); next)
current = next;
else
current = current->set_next(ch, &pool[currAlloc++]);
}
current->terminate = true;
}
...
}
Oh and can you see how I allocate the next CharNode? Yes, just by simple counter and give the address of the object! This is basically how std::vector works internally (without handling array extension in case of the vector is full when inserting).
4. Reserve the string to preallocate enough space for our return sentence
We know that the return value will not be larger than the previous sentence. So, just allocate as many as it requires. Don’t forget to add one for null character! (Although many implementation should have already add one extra character for null character when calling reserve, but just to be sure. 1 byte does not kill you)
std::string replaceWords(std::vector<std::string> const& dictionary, std::string const& sentence)
{
...
std::string ret;
ret.reserve(sentence.size() + 1);
...
}
5. Single-pass Parsing Like C++ Compiler
Why parsing with multiple times looping and copying unnecessarily. That’s not how LLVM works. Do it single pass-ly! Making a simple parser requires building a state machine. Since our requirement is simple, we can just have three state plus one condition here:
- CONSUME – It means we are consuming the character to the lexer tree and emitting the current character to the output.
- TRIM – We reached the node in the lexer tree that indicates end of word, means we found the shortest word. We then ignore the rest of the character until we reach next whitespace.
- IGNORE – We cannot reach any node in the lexer tree that indicates the end of word. Therefore, this word does not match to any suitable prefix in our dictionary, then we can emit the rest of the character until we reach the next whitespace.
- When we reach a whitespace character, we reset our state machine to CONSUME.
And then we build the simple loop for this state machine:
std::string replaceWords(std::vector<std::string> const& dictionary, std::string const& sentence)
{
...
enum {
CONSUME,
TRIM,
IGNORE
} state { CONSUME };
CharNode* current = &root;
for(auto ch : sentence)
{
if(ch == ' ')
{
state = CONSUME;
current = &root;
ret.append(1, ch);
continue;
}
switch (state)
{
case CONSUME:
if(current->terminate)
{
state = TRIM;
continue;
}
else if(auto next = current->get_next(ch); next)
current = next;
else
state = IGNORE;
break;
case TRIM:
continue;
case IGNORE:
break;
}
ret.append(1, ch);
}
return ret;
}
How’s The Result
The best result I could get was 38ms. But when I resubmitted again, it always around 45ms. So lower value than that was kind of lucky.
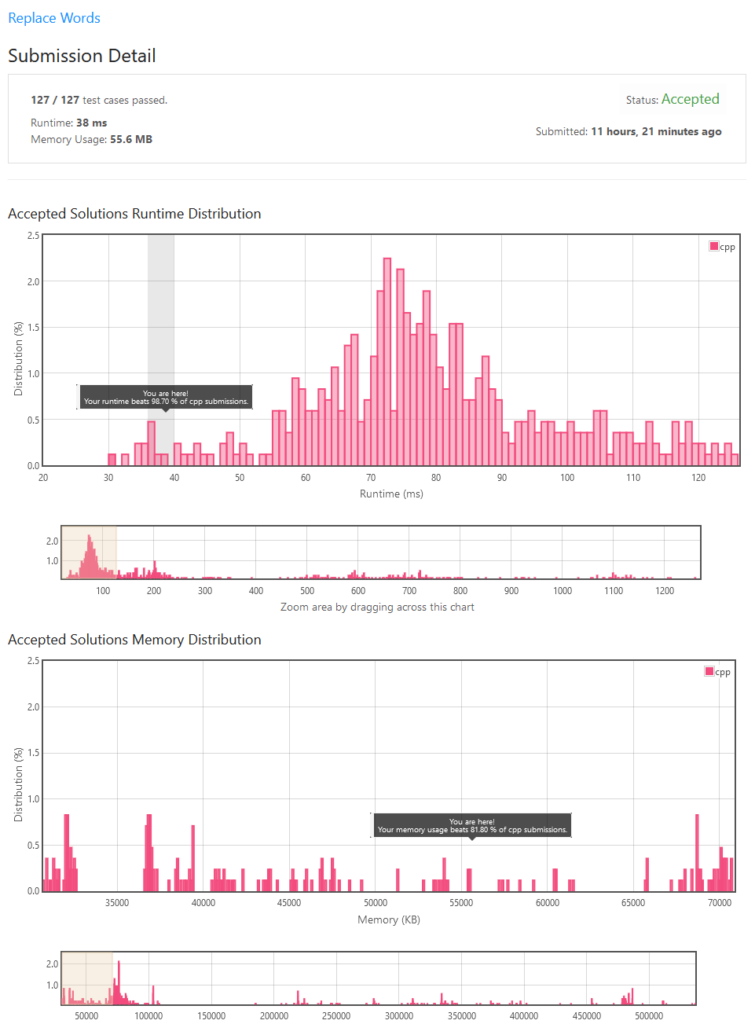
But wait, let’s rewrite this in C as it is extremely simple and does not need to implement weird algorithm such as sorting. So I did, and here’s the result:
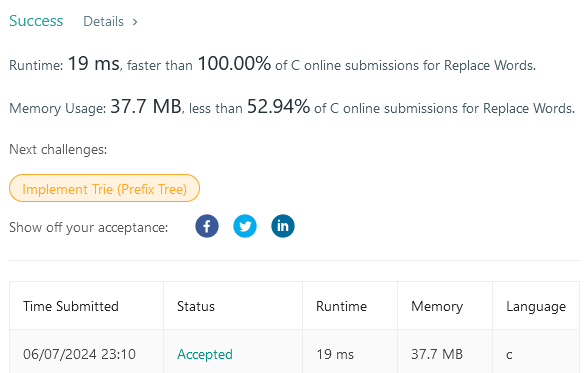
The other solution was in 31 ms order, mostly on 60ms, and even 180ms lol.
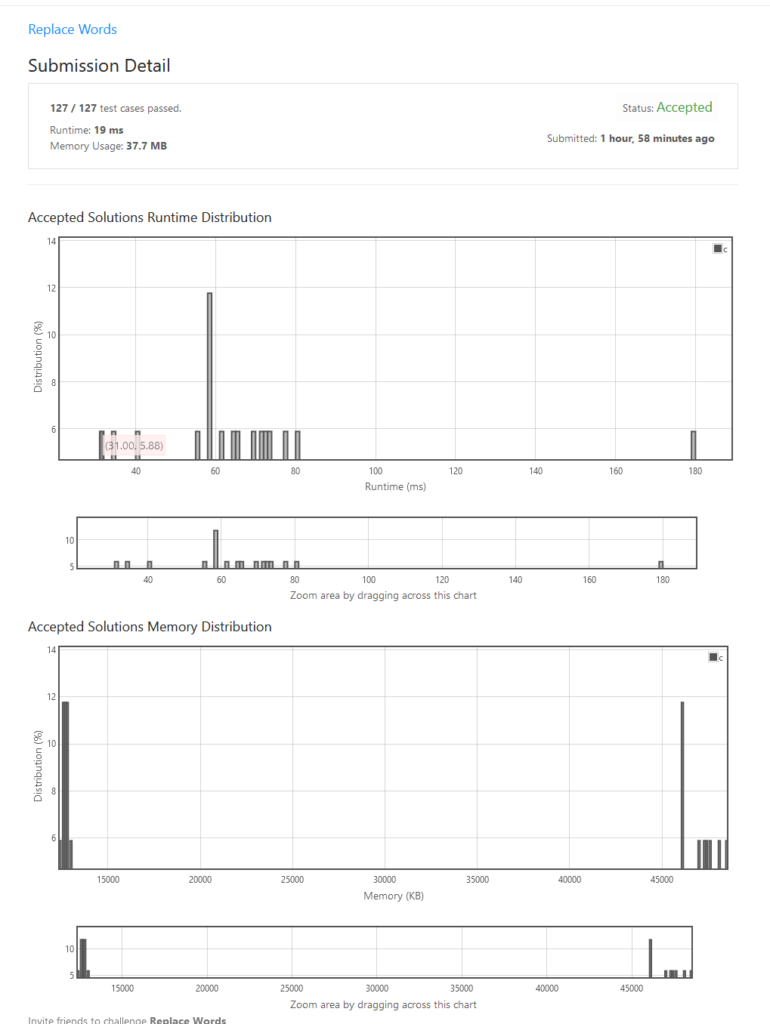
But why they are slower?
- The slower code 60ms uses qsort function to sort the dictionary words, then for each word in the sentence it performed memcmp to to compare word in the sentence and the dictionary. This in turns saves lots of memory (only 12.6MB used) because it does not need to allocate big chunk of lexer tree to parse the sentence. But still, slow. Also, their implementation do everything in place, including the returned string which they did not malloc new string, rather used the existing sentence and change in place. Since it is not described by the problem statement, I guess this is a good optimization point
- The implementation that uses tree reaches 31ms. It is slower than my implementation because, again, malloc in every tree insertion, and they do the operation using recursion. So it also becomes the solution with the largest memory requirement, which reaches 48.5MB instead of mine only 37.7MB
The Caveat
Don’t code Java in C++. Carefully consider your allocation AND HOW YOU PASS std::string!!!